
The problem
Scuba divers communicate through hand signals — a standardised vocabulary of gestures for marine animals, instructions, and hazards. Underwater, it is the only language available.
The question was whether a computer vision model could learn to read that language. The harder question was where to get the training data. Collecting real underwater footage of divers performing specific signals, at volume, with ground-truth labels, is expensive, slow, and requires a wetsuit.
The answer: don’t. Generate it instead.

Synthetic data pipeline
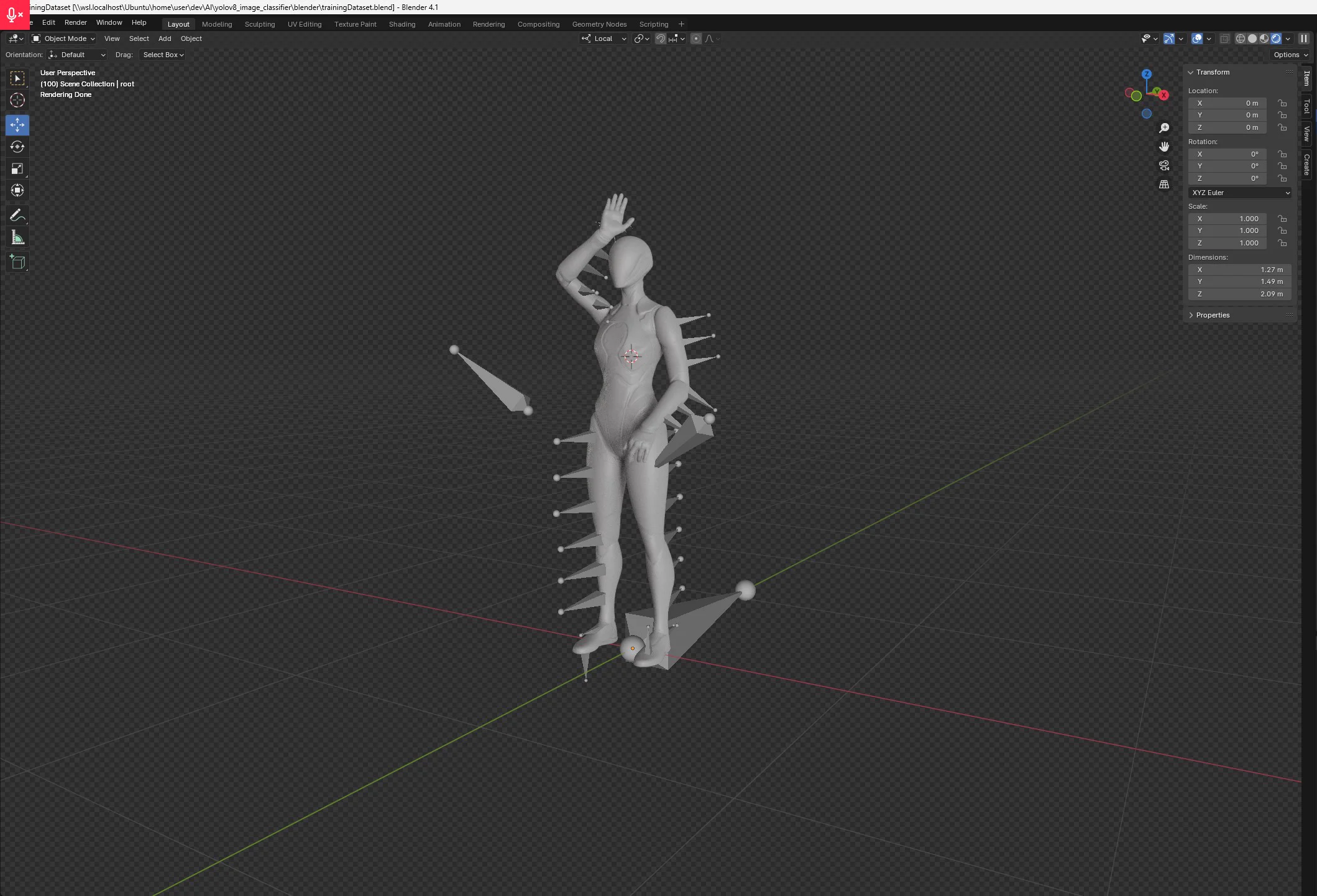
The training dataset was generated entirely from 3D. A rigged human figure was posed in the target hand signals, placed in a virtual environment, and rendered from multiple angles under varying lighting conditions. Hundreds of training images per class — no pool required.

- Three target classes — Bluespotted ray, Octopus, Shark. Each a distinct hand signal with different hand shape, position, and motion.
- Varied conditions — multiple camera angles, lighting variations, and background conditions per signal, to prevent the model from learning shortcuts.
Training results
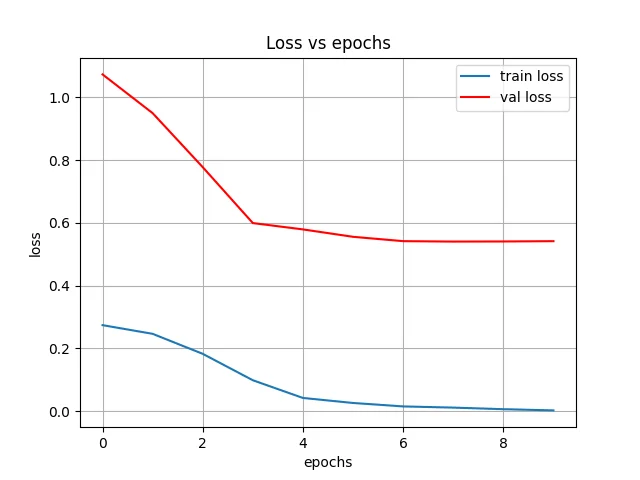
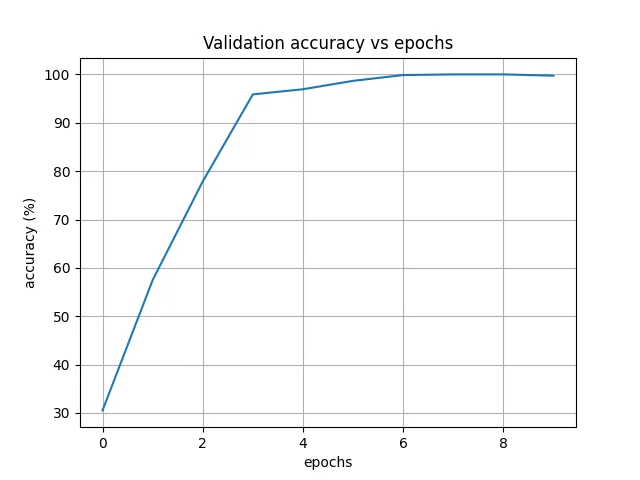
A convolutional neural network trained on the synthetic dataset. Validation accuracy reached ~100% within 10 epochs — the model learning to distinguish the three signals cleanly despite having never seen a real diver perform them.
Real-world inference
The model trained on synthetic renders was then tested against real photographs of divers performing the same signals. It had never seen real images during training.

Test 1 — Shark — score 0.9995 for shark, near-zero for all other classes. Correct.

Test 2 — Octopus — score 0.9468 for octopus (vs 0.0279 / 0.0253). Correct, despite being shot out of water.
What this shows
- Synthetic → real transfer — a model trained exclusively on 3D renders correctly classified real-world photographs it had never seen, demonstrating that synthetic data can generalise beyond its generation domain.
- No real data required — the entire training dataset was generated without collecting a single real image. For domains where data collection is difficult, dangerous, or expensive, this is the practical alternative.
- Domain gap handled — the octopus signal was correctly identified from a surface photograph: different environment, different lighting, different everything from the underwater training renders.